Data Store Types
Neuroverse supports a number of data store types each covering a different set of use cases relevant to an overall data pipeline.
The use cases intended for each data store type are described later in this section.
Data Store Type Limits
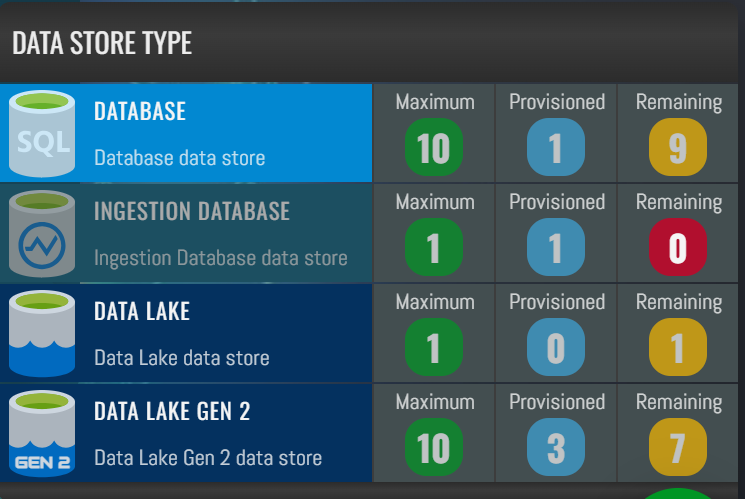
There is a limit governing the number of data stores of each type that may be provisioned in a tenant as shown in the image below.
The limits have been set in line with the intended use caes for each type.
Data Store Type Use Cases
| Data Store Type | Limit | Description | Use Case |
|---|---|---|---|
| Database | 10 | A SQL database of configurable size and performance | Suitable for storage of relational data that is the target of reporting queries or ad-hoc analysis using SQL syntax queries |
| Ingestion Database | 1 | A SQL Database used specifically as the target for data ingested using Neuroverse’s Data Ingestion service intended for small to moderately sized batch data that can be appended, updated and removed | Used when data ingestion make use of Neuroverse’s Data Ingestion service. NOTE: In most cases, the use of a Data Lake and an associated data pipeline is preferable to the Data Ingestion service |
| Data Lake | 1 | A store for structured and unstructured data organised conceptually as folders and files | Deprecated. Use Data Lake Gen 2 instead |
| Data Lake Gen 2 | 10 | A store for structured and unstructured data organised conceptually as folders and files | Recommended in most cases. An architecture involving the storage of raw data that is then processed and transformed may involve several Data Lake stores. Typically, data will be stored first in a Data Lake and processed through a pipeline that may result in generated results being stored in a Database for reporting |